The hottest topic in the technology sector right now is undoubtedly the rise of Artificial Intelligence (AI). AI, in its current form, has revolutionized the way we interact with technology, and at the forefront of this transformation are Large Language Models (LLMs). These LLM-based AI systems, such as OpenAI’s (Chat) GPT, DeepSeek, Google Gemini, and similar models, use deep learning to understand and generate human-like text. They analyze vast amounts of text data, learning patterns and relationships between words, which enables them to answer questions, generate reports, summarize legal documents, and assist in decision-making.
How Large Language Models Work
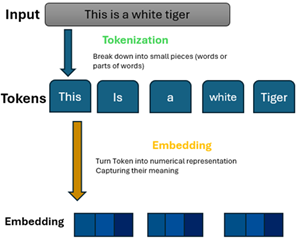
At their core, large language models (LLMs) rely on neural networks—loosely inspired by neurons in the human brain—trained on massive datasets composed of text. Multimodal models, such as ChatGPT-4o and Google Gemini, are trained on other types of data, including images, sounds, and videos. As previously mentioned, deep learning is a subset of machine learning that employs neural networks to process data from a dataset and form numerical relationships for each unit of data, known as a token. Tokens are the individual units of data that an LLM associates with a specific word, character, or piece of punctuation.
By using an architecture called a transformer, these models can process language with remarkable accuracy by forming and refining relationships between tokens. This enables them to predict the next word in a sentence based on the context provided by these token relationships, allowing for the generation of coherent and semantically context-aware responses. However, LLMs do not possess a fundamental understanding of the human-centric information they are trained on or generate, which is why it is essential to vet any output for accuracy.

For instance, Meta’s LLaMA 3 open-weight model was trained on a dataset of more than 15 trillion tokens, or approximately 44 TB of data. Training models of this size requires substantial computing power and is typically limited to data centers operated by tech companies such as Google, Amazon, and Microsoft, which can handle the immense computational demands. However, unlike traditional keyword-based search systems, LLMs can understand nuances, enabling much more sophisticated forms of assistance.
 A newer trend is the rise of edge device LLMs, which run locally on smartphones and other devices rather than relying solely on cloud-based processing. These models—such as Apple’s on-device AI and desktop apps like “LocalLLM” powered by Ollama—bring AI closer to users while addressing potential privacy concerns. By keeping data on the device, edge LLMs reduce reliance on internet connectivity, increase response speed, and offer improved security, making them ideal for sensitive environments like government offices.
A newer trend is the rise of edge device LLMs, which run locally on smartphones and other devices rather than relying solely on cloud-based processing. These models—such as Apple’s on-device AI and desktop apps like “LocalLLM” powered by Ollama—bring AI closer to users while addressing potential privacy concerns. By keeping data on the device, edge LLMs reduce reliance on internet connectivity, increase response speed, and offer improved security, making them ideal for sensitive environments like government offices.
Implementing Large Language Models (LLMs) in a government office like the Clerk of Courts can enhance efficiency but requires careful attention to security due to the sensitive nature of legal documents and personal information. Here’s how such offices can securely integrate LLMs:
- On-Site AI Systems: Instead of using cloud-based LLMs, courts can install private AI models within their own facilities. This approach keeps data processing internal, minimizing the risk of data breaches. Models like Meta’s Llama 3 or customized versions of Google’s Gemma can be tailored to meet specific legal requirements.
- Controlled Access: Only authorized staff should have access to the AI systems. Implementing measures like multi-factor authentication (MFA) and role-based permissions ensures that sensitive information is accessible only to those with proper clearance.
- Data Encryption and Compliance: All data handled by the AI, both incoming and outgoing, should be encrypted during transmission and while stored. Government offices must adhere to relevant regulations to safeguard legal data.
- Activity Monitoring: Every interaction with the AI should be recorded for auditing purposes. For instance, if the AI generates a legal summary, that output should be securely stored and reviewed for accuracy.
By carefully and securely integrating LLMs, Clerk of Courts offices can improve document processing, assist with legal research, and automate routine tasks, all while ensuring compliance and protecting sensitive data. With the right precautions, AI has the potential to significantly enhance efficiency in the legal sector without compromising privacy.